Stacking Models
Scalecast allows you to stack models of different classes together.
You can add the predictions of any given model to the
Forecasterobject as a covariate, which scalecast refers to as “signals”. This is through the use of theForecaster.add_signals()method. See the documentation.These signals can come from any model class available in scalecast and are treated the same as any other covariate. They can be combined with other covariates (such as series lags, seasonal representations, and trends). They can also be added to an
MVForecasterobject for multivariate forecasting. The signals from Meta Prophet or LinkedIn Silverkite, which add holiday effects to models, can be added to the objects to capture the uniqueness of these models’ specifications.We will use symmetric mean percentage error (SMAPE) to measure the performance of each model in this notebook.
Requirements:
scalecast>=0.17.9tensorflowshapData source: M4
[1]:
import pandas as pd
import numpy as np
from scalecast.Forecaster import Forecaster
from scalecast.util import metrics
import matplotlib.pyplot as plt
import seaborn as sns
[2]:
def read_data(idx = 'H1', cis = True, metrics = ['smape']):
info = pd.read_csv(
'M4-info.csv',
index_col=0,
parse_dates=['StartingDate'],
dayfirst=True,
)
train = pd.read_csv(
f'Hourly-train.csv',
index_col=0,
).loc[idx]
test = pd.read_csv(
f'Hourly-test.csv',
index_col=0,
).loc[idx]
y = train.values
sd = info.loc[idx,'StartingDate']
fcst_horizon = info.loc[idx,'Horizon']
cd = pd.date_range(
start = sd,
freq = 'H',
periods = len(y),
)
f = Forecaster(
y = y,
current_dates = cd,
future_dates = fcst_horizon,
test_length = fcst_horizon,
cis = cis,
metrics = metrics,
)
return f, test.values
[3]:
f, test_set = read_data()
f
[3]:
Forecaster(
DateStartActuals=2015-07-12T08:00:00.000000000
DateEndActuals=2015-08-10T11:00:00.000000000
Freq=H
N_actuals=700
ForecastLength=48
Xvars=[]
TestLength=48
ValidationMetric=smape
ForecastsEvaluated=[]
CILevel=0.95
CurrentEstimator=mlr
GridsFile=Grids
)
We are using the H1 series from the M4 competition, but you can change the value passed to the idx argument in the function above to test this same analysis with any hourly series in the dataset.
EDA
[4]:
f.plot()
plt.show()
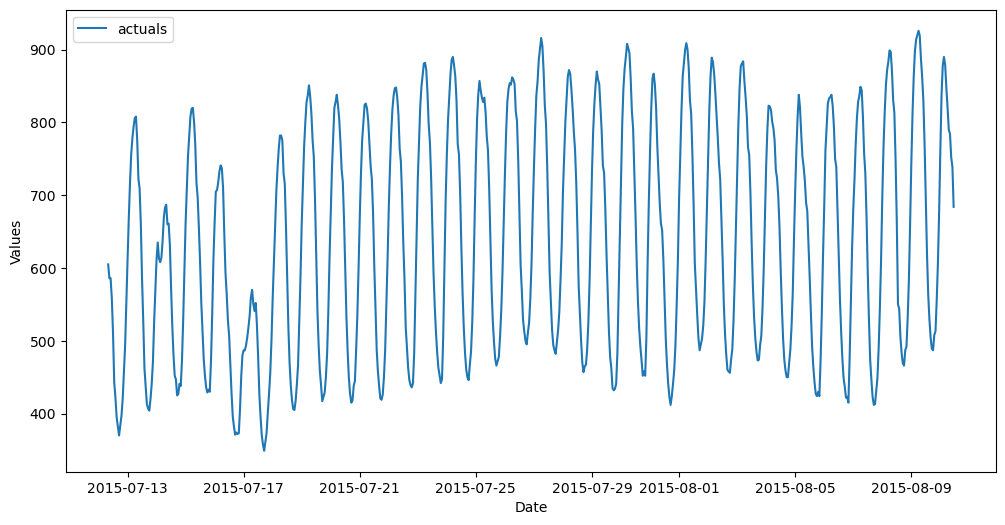
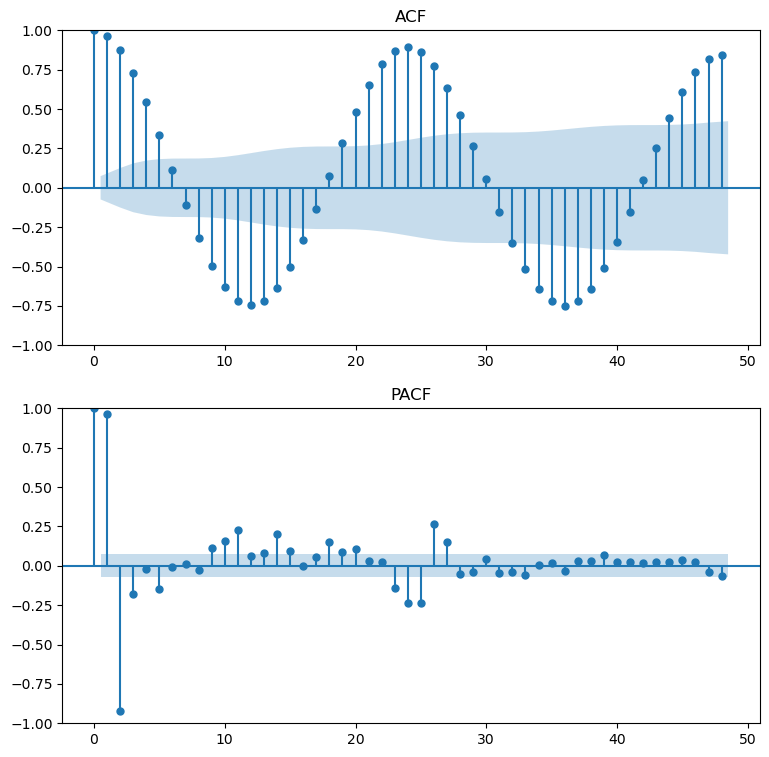
ACF/PACF at Series Level
[5]:
figs, axs = plt.subplots(2, 1,figsize=(9,9))
f.plot_acf(ax=axs[0],title='ACF',lags=48)
f.plot_pacf(ax=axs[1],title='PACF',lags=48,method='ywm')
plt.show()
Augmented Dickey-Fuller Test
[6]:
critical_pval = 0.05
print('Augmented Dickey-Fuller results:')
stat, pval, _, _, _, _ = f.adf_test(full_res=True)
print('the test-stat value is: {:.2f}'.format(stat))
print('the p-value is {:.4f}'.format(pval))
print('the series is {}'.format('stationary' if pval < critical_pval else 'not stationary'))
print('-'*100)
Augmented Dickey-Fuller results:
the test-stat value is: -2.06
the p-value is 0.2623
the series is not stationary
----------------------------------------------------------------------------------------------------
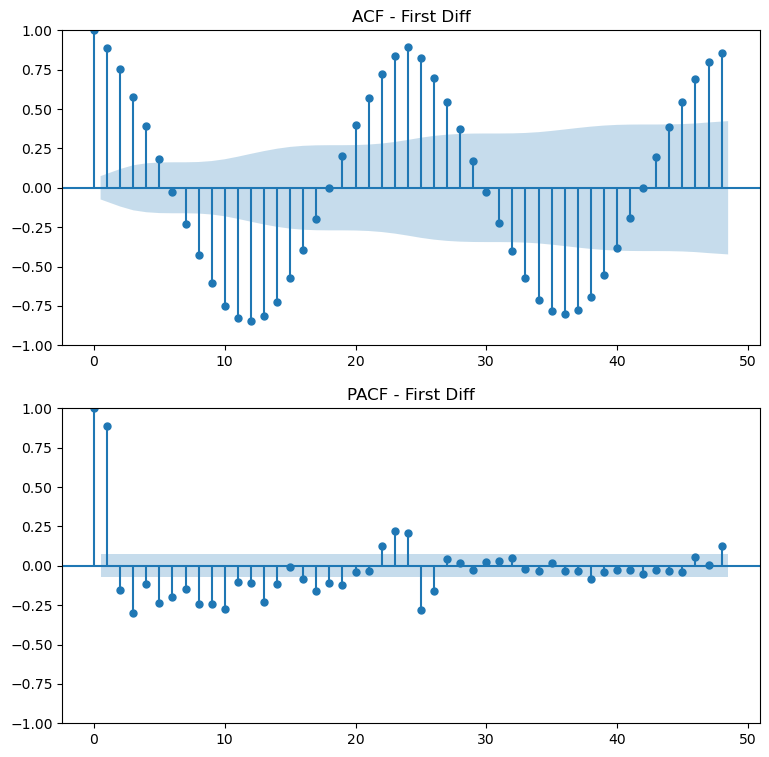
ACF/PACF at Series First Difference
[7]:
figs, axs = plt.subplots(2, 1,figsize=(9,9))
f.plot_acf(ax=axs[0],title='ACF - First Diff',lags=48,diffy=1)
f.plot_pacf(ax=axs[1],title='PACF - First Diff',lags=48,diffy=1,method='ywm')
plt.show()
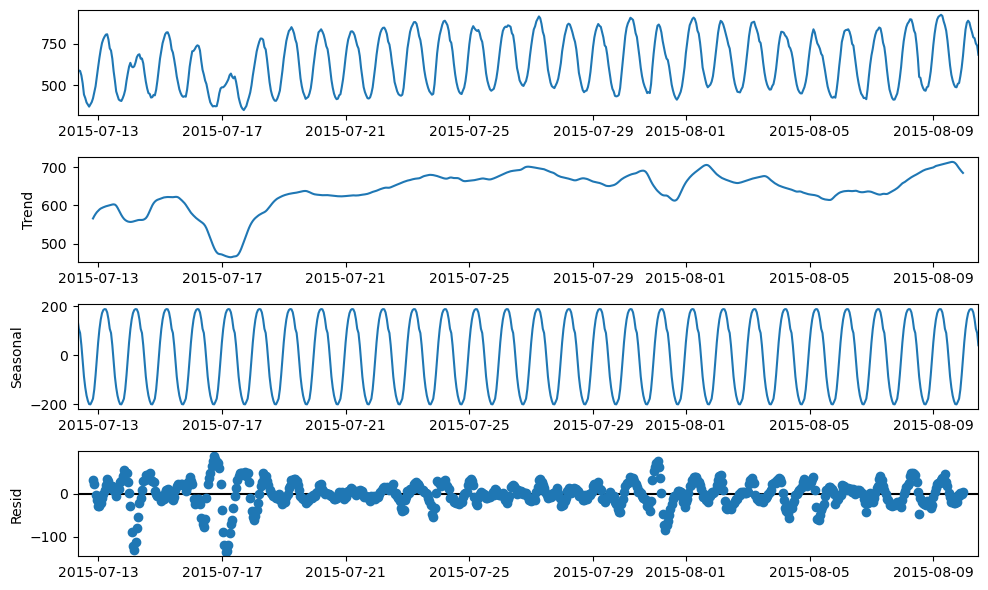
Seasonal Decomp
[8]:
plt.rc("figure",figsize=(10,6))
f.seasonal_decompose().plot()
plt.show()
Naive
This will serve as a benchmark model
It will propagate the last 24 observations in a “seasonal naive” model
[9]:
f.set_estimator('naive')
f.manual_forecast(seasonal=True)
ARIMA
Manual ARIMA: (5,1,4) x (1,1,1,24)
[10]:
f.set_estimator('arima')
f.manual_forecast(
order = (5,1,4),
seasonal_order = (1,1,1,24),
call_me = 'manual_arima',
)
RNN
Tanh Activation
[11]:
f.set_estimator('rnn')
f.manual_forecast(
lags = 48,
layers_struct=[
('LSTM',{'units':100,'activation':'tanh'}),
('LSTM',{'units':100,'activation':'tanh'}),
('LSTM',{'units':100,'activation':'tanh'}),
],
optimizer = 'Adam',
epochs = 15,
plot_loss = True,
validation_split=0.2,
call_me = 'rnn_tanh_activation',
)
2023-04-11 11:12:28.428651: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: SSE4.1 SSE4.2
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2023-04-11 11:12:30.032138: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: SSE4.1 SSE4.2
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
Epoch 1/15
14/14 [==============================] - 4s 110ms/step - loss: 0.3419 - val_loss: 0.2452
Epoch 2/15
14/14 [==============================] - 1s 60ms/step - loss: 0.2546 - val_loss: 0.2347
Epoch 3/15
14/14 [==============================] - 1s 60ms/step - loss: 0.2472 - val_loss: 0.2255
Epoch 4/15
14/14 [==============================] - 1s 60ms/step - loss: 0.2175 - val_loss: 0.1654
Epoch 5/15
14/14 [==============================] - 1s 60ms/step - loss: 0.1365 - val_loss: 0.0813
Epoch 6/15
14/14 [==============================] - 1s 60ms/step - loss: 0.0946 - val_loss: 0.0664
Epoch 7/15
14/14 [==============================] - 1s 60ms/step - loss: 0.0818 - val_loss: 0.0677
Epoch 8/15
14/14 [==============================] - 1s 60ms/step - loss: 0.0796 - val_loss: 0.0649
Epoch 9/15
14/14 [==============================] - 1s 60ms/step - loss: 0.0792 - val_loss: 0.0839
Epoch 10/15
14/14 [==============================] - 1s 60ms/step - loss: 0.0820 - val_loss: 0.0539
Epoch 11/15
14/14 [==============================] - 1s 60ms/step - loss: 0.0756 - val_loss: 0.0577
Epoch 12/15
14/14 [==============================] - 1s 60ms/step - loss: 0.0731 - val_loss: 0.0549
Epoch 13/15
14/14 [==============================] - 1s 60ms/step - loss: 0.0716 - val_loss: 0.0520
Epoch 14/15
14/14 [==============================] - 1s 60ms/step - loss: 0.0727 - val_loss: 0.0692
Epoch 15/15
14/14 [==============================] - 1s 60ms/step - loss: 0.0750 - val_loss: 0.0494
1/1 [==============================] - 1s 597ms/step
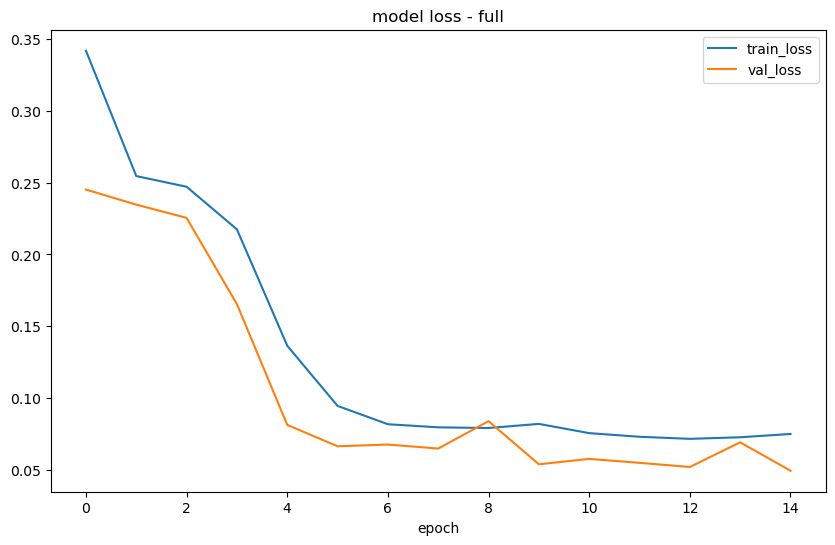
Epoch 1/15
16/16 [==============================] - 4s 100ms/step - loss: 0.3369 - val_loss: 0.2541
Epoch 2/15
16/16 [==============================] - 1s 58ms/step - loss: 0.2487 - val_loss: 0.2471
Epoch 3/15
16/16 [==============================] - 1s 58ms/step - loss: 0.2394 - val_loss: 0.2292
Epoch 4/15
16/16 [==============================] - 1s 58ms/step - loss: 0.1850 - val_loss: 0.1042
Epoch 5/15
16/16 [==============================] - 1s 58ms/step - loss: 0.0980 - val_loss: 0.0995
Epoch 6/15
16/16 [==============================] - 1s 58ms/step - loss: 0.0870 - val_loss: 0.0737
Epoch 7/15
16/16 [==============================] - 1s 58ms/step - loss: 0.0817 - val_loss: 0.0661
Epoch 8/15
16/16 [==============================] - 1s 58ms/step - loss: 0.0778 - val_loss: 0.0695
Epoch 9/15
16/16 [==============================] - 1s 58ms/step - loss: 0.0751 - val_loss: 0.0639
Epoch 10/15
16/16 [==============================] - 1s 58ms/step - loss: 0.0712 - val_loss: 0.0687
Epoch 11/15
16/16 [==============================] - 1s 58ms/step - loss: 0.0693 - val_loss: 0.0553
Epoch 12/15
16/16 [==============================] - 1s 58ms/step - loss: 0.0694 - val_loss: 0.0730
Epoch 13/15
16/16 [==============================] - 1s 58ms/step - loss: 0.0691 - val_loss: 0.0654
Epoch 14/15
16/16 [==============================] - 1s 58ms/step - loss: 0.0742 - val_loss: 0.0580
Epoch 15/15
16/16 [==============================] - 1s 58ms/step - loss: 0.0695 - val_loss: 0.0619
1/1 [==============================] - 1s 750ms/step
19/19 [==============================] - 0s 18ms/step
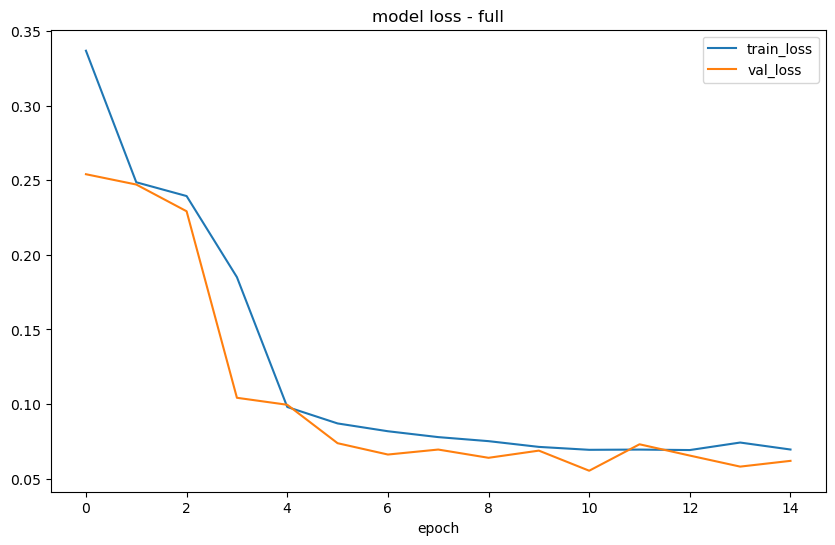
Relu Activation
[12]:
f.manual_forecast(
lags = 48,
layers_struct=[
('LSTM',{'units':100,'activation':'relu'}),
('LSTM',{'units':100,'activation':'relu'}),
('LSTM',{'units':100,'activation':'relu'}),
],
optimizer = 'Adam',
epochs = 15,
plot_loss = True,
validation_split=0.2,
call_me = 'rnn_relu_activation',
)
Epoch 1/15
14/14 [==============================] - 3s 79ms/step - loss: 0.4613 - val_loss: 0.3487
Epoch 2/15
14/14 [==============================] - 1s 58ms/step - loss: 0.3115 - val_loss: 0.2559
Epoch 3/15
14/14 [==============================] - 1s 58ms/step - loss: 0.2579 - val_loss: 0.2363
Epoch 4/15
14/14 [==============================] - 1s 58ms/step - loss: 0.2497 - val_loss: 0.2378
Epoch 5/15
14/14 [==============================] - 1s 58ms/step - loss: 0.2489 - val_loss: 0.2359
Epoch 6/15
14/14 [==============================] - 1s 59ms/step - loss: 0.2472 - val_loss: 0.2339
Epoch 7/15
14/14 [==============================] - 1s 58ms/step - loss: 0.2458 - val_loss: 0.2316
Epoch 8/15
14/14 [==============================] - 1s 58ms/step - loss: 0.2434 - val_loss: 0.2271
Epoch 9/15
14/14 [==============================] - 1s 58ms/step - loss: 0.2369 - val_loss: 0.2280
Epoch 10/15
14/14 [==============================] - 1s 58ms/step - loss: 0.2184 - val_loss: 0.1833
Epoch 11/15
14/14 [==============================] - 1s 58ms/step - loss: 0.1880 - val_loss: 0.1520
Epoch 12/15
14/14 [==============================] - 1s 58ms/step - loss: 0.1474 - val_loss: 0.1007
Epoch 13/15
14/14 [==============================] - 1s 58ms/step - loss: 0.1102 - val_loss: 0.0854
Epoch 14/15
14/14 [==============================] - 1s 58ms/step - loss: 0.1007 - val_loss: 0.0715
Epoch 15/15
14/14 [==============================] - 1s 58ms/step - loss: 0.0889 - val_loss: 0.0715
1/1 [==============================] - 0s 232ms/step
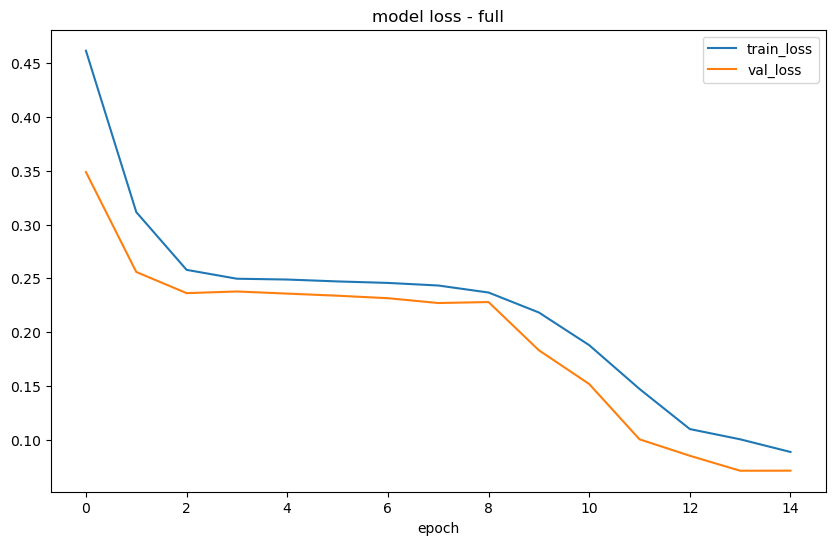
Epoch 1/15
16/16 [==============================] - 3s 75ms/step - loss: 0.4379 - val_loss: 0.3125
Epoch 2/15
16/16 [==============================] - 1s 56ms/step - loss: 0.3162 - val_loss: 0.2632
Epoch 3/15
16/16 [==============================] - 1s 56ms/step - loss: 0.2509 - val_loss: 0.2509
Epoch 4/15
16/16 [==============================] - 1s 56ms/step - loss: 0.2444 - val_loss: 0.2482
Epoch 5/15
16/16 [==============================] - 1s 56ms/step - loss: 0.2433 - val_loss: 0.2482
Epoch 6/15
16/16 [==============================] - 1s 57ms/step - loss: 0.2427 - val_loss: 0.2468
Epoch 7/15
16/16 [==============================] - 1s 56ms/step - loss: 0.2426 - val_loss: 0.2459
Epoch 8/15
16/16 [==============================] - 1s 56ms/step - loss: 0.2401 - val_loss: 0.2415
Epoch 9/15
16/16 [==============================] - 1s 56ms/step - loss: 0.2348 - val_loss: 0.2317
Epoch 10/15
16/16 [==============================] - 1s 56ms/step - loss: 0.2169 - val_loss: 0.1917
Epoch 11/15
16/16 [==============================] - 1s 56ms/step - loss: 0.2309 - val_loss: 0.2104
Epoch 12/15
16/16 [==============================] - 1s 56ms/step - loss: 0.1792 - val_loss: 0.1393
Epoch 13/15
16/16 [==============================] - 1s 56ms/step - loss: 0.1294 - val_loss: 0.0986
Epoch 14/15
16/16 [==============================] - 1s 56ms/step - loss: 0.0959 - val_loss: 0.0779
Epoch 15/15
16/16 [==============================] - 1s 56ms/step - loss: 0.0890 - val_loss: 0.0783
1/1 [==============================] - 0s 232ms/step
19/19 [==============================] - 0s 18ms/step
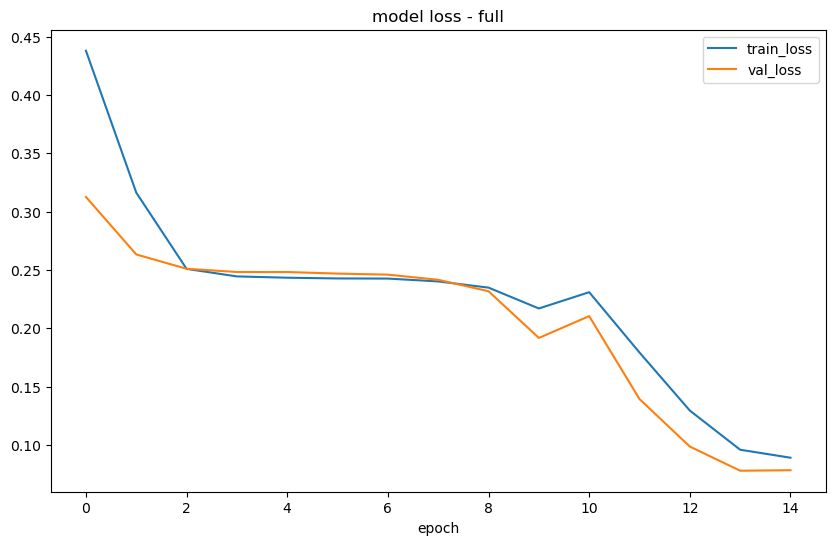
Prophet
[13]:
f.set_estimator('prophet')
f.manual_forecast()
11:13:36 - cmdstanpy - INFO - Chain [1] start processing
11:13:36 - cmdstanpy - INFO - Chain [1] done processing
11:13:36 - cmdstanpy - INFO - Chain [1] start processing
11:13:36 - cmdstanpy - INFO - Chain [1] done processing
Compare Results
[14]:
results = f.export(determine_best_by='TestSetSMAPE')
ms = results['model_summaries']
ms[
[
'ModelNickname',
'TestSetLength',
'TestSetSMAPE',
'InSampleSMAPE',
]
]
[14]:
| ModelNickname | TestSetLength | TestSetSMAPE | InSampleSMAPE | |
|---|---|---|---|---|
| 0 | manual_arima | 48 | 0.046551 | 0.017995 |
| 1 | prophet | 48 | 0.047237 | 0.043859 |
| 2 | rnn_relu_activation | 48 | 0.082511 | 0.081514 |
| 3 | naive | 48 | 0.093079 | 0.067697 |
| 4 | rnn_tanh_activation | 48 | 0.096998 | 0.059914 |
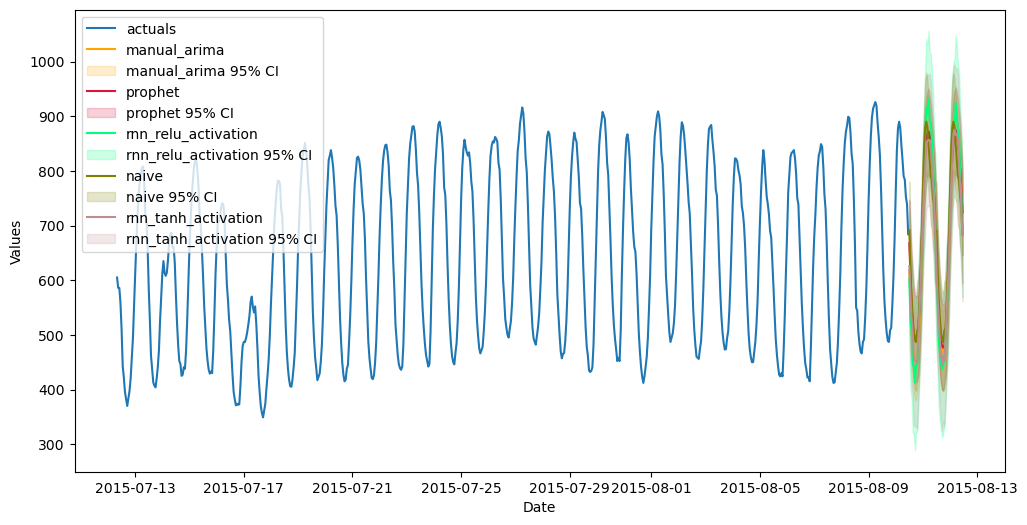
Using the last 48 observations in the Forecaster object to test each model, the arima model performed the best.
Plot Results
[15]:
f.plot(order_by="TestSetSMAPE",ci=True)
plt.show()
[16]:
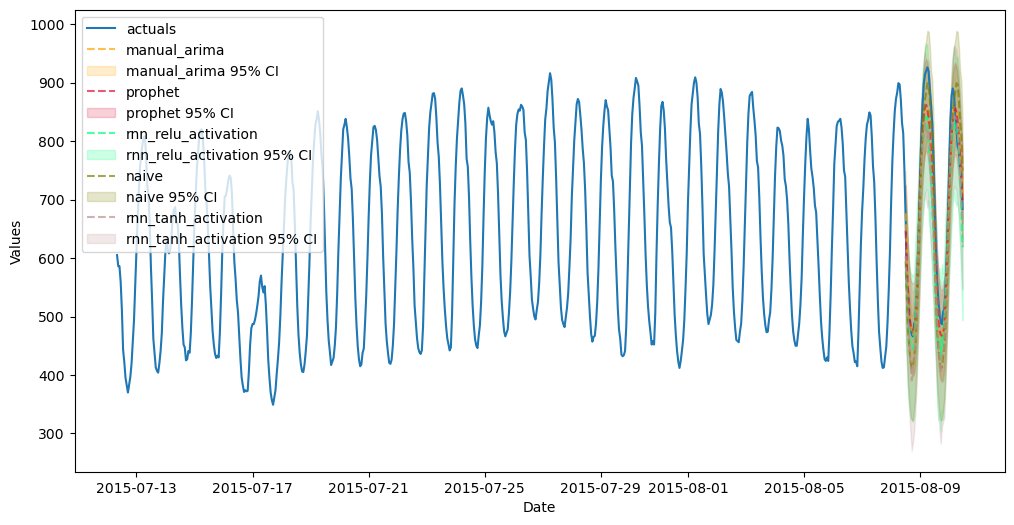
f.plot_test_set(order_by="TestSetSMAPE",ci=True)
plt.show()
Stack Models
To stack models in scalecast, you can either use the StackingRegressor from scikit-learn, or you can add the predictions from already-evaluated models into the
Forecasterobject usingForecaster.add_signals(). The latter approach is more advantageous as it can do everything that can be done with the StackingRegressor, but it can use non scikit-learn model classes, can more flexibly use other regressors, and is easier to tune.In the below example, we are using the signals generated from two LSTM models, an ARIMA model, a naive model, and Meta Prophet. We will also add the last 48 series lags to the object.
One key point in the function below: we are specifying the
train_onlyargument as False. This means that our test set will be compromised as we will introduce leakage from the other models. I chose to leave it False because this approach will ultimately be tested with a separate out-of-sample test set. The rule of thumb around this is to make this argument True if you want to report accurate test-set metrics but leave False when you want to deliver a Forecast into a future horizon. You can run this function twice with each option specified if you want to do both–run first time withtrain_only=True, evaluate models, and check the test-set metrics. Then, rerun withtrain_only=Falseand re-evaluate models to deliver future point predictions.
[17]:
f.add_ar_terms(48)
f.add_signals(
f.history.keys(),
#train_only = True, # uncomment to avoid leakage into the test set
)
f.set_estimator('catboost')
f
[17]:
Forecaster(
DateStartActuals=2015-07-12T08:00:00.000000000
DateEndActuals=2015-08-10T11:00:00.000000000
Freq=H
N_actuals=700
ForecastLength=48
Xvars=['AR1', 'AR2', 'AR3', 'AR4', 'AR5', 'AR6', 'AR7', 'AR8', 'AR9', 'AR10', 'AR11', 'AR12', 'AR13', 'AR14', 'AR15', 'AR16', 'AR17', 'AR18', 'AR19', 'AR20', 'AR21', 'AR22', 'AR23', 'AR24', 'AR25', 'AR26', 'AR27', 'AR28', 'AR29', 'AR30', 'AR31', 'AR32', 'AR33', 'AR34', 'AR35', 'AR36', 'AR37', 'AR38', 'AR39', 'AR40', 'AR41', 'AR42', 'AR43', 'AR44', 'AR45', 'AR46', 'AR47', 'AR48', 'signal_naive', 'signal_manual_arima', 'signal_rnn_tanh_activation', 'signal_rnn_relu_activation', 'signal_prophet']
TestLength=48
ValidationMetric=smape
ForecastsEvaluated=['naive', 'manual_arima', 'rnn_tanh_activation', 'rnn_relu_activation', 'prophet']
CILevel=0.95
CurrentEstimator=catboost
GridsFile=Grids
)
[18]:
f.manual_forecast(
Xvars='all',
call_me='catboost_all_reg',
verbose = False,
)
f.save_feature_importance(method = 'shap') # it would be interesting to see the shapley scores (later)
f.manual_forecast(
Xvars=[x for x in f.get_regressor_names() if x.startswith('AR')],
call_me = 'catboost_lags_only',
verbose = False,
)
f.manual_forecast(
Xvars=[x for x in f.get_regressor_names() if not x.startswith('AR')],
call_me = 'catboost_signals_only',
verbose = False,
)
[19]:
results = f.export(determine_best_by='TestSetSMAPE')
ms = results['model_summaries']
ms[
[
'ModelNickname',
'TestSetLength',
'TestSetSMAPE',
'InSampleSMAPE',
]
]
[19]:
| ModelNickname | TestSetLength | TestSetSMAPE | InSampleSMAPE | |
|---|---|---|---|---|
| 0 | catboost_signals_only | 48 | 0.014934 | 0.007005 |
| 1 | catboost_all_reg | 48 | 0.022299 | 0.003340 |
| 2 | manual_arima | 48 | 0.046551 | 0.017995 |
| 3 | prophet | 48 | 0.047237 | 0.043859 |
| 4 | catboost_lags_only | 48 | 0.060460 | 0.003447 |
| 5 | rnn_relu_activation | 48 | 0.082511 | 0.081514 |
| 6 | naive | 48 | 0.093079 | 0.067697 |
| 7 | rnn_tanh_activation | 48 | 0.096998 | 0.059914 |
Unsuprisingly, now our catboost model with just the signals is showing the best test-set scores. But the test set has been compromised for all models that used signals as inputs. A way around that would have been to call add_signals(train_only=True). Another way to really know how these models performed out-of-sample, we need to compare it with a separate out-of-sample test set.
Check Performance of Forecast on Held-Out Sample
[20]:
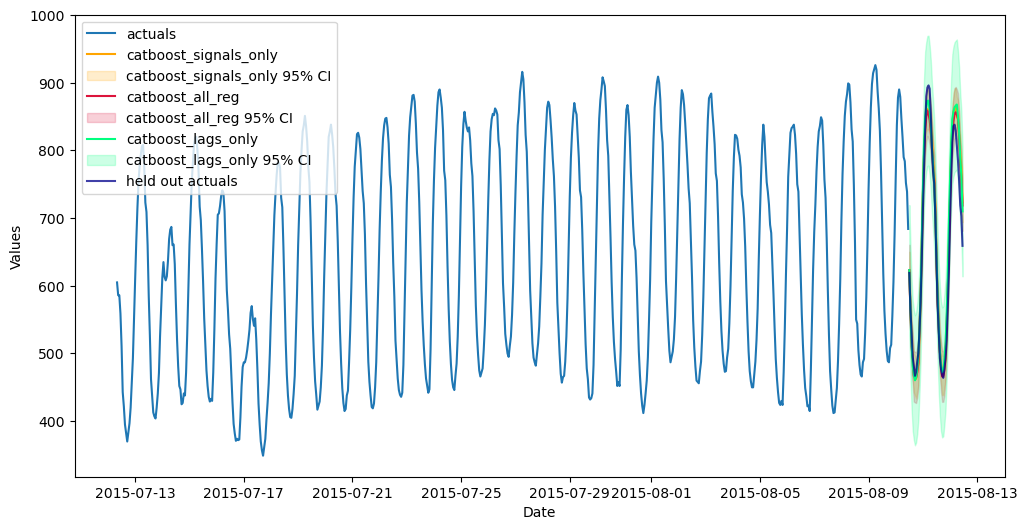
fig, ax = plt.subplots(figsize=(12,6))
f.plot(
models = [m for m in f.history if m.startswith('catboost')],
order_by="TestSetSMAPE",
ci=True,
ax = ax
)
sns.lineplot(
x = f.future_dates,
y = test_set,
ax = ax,
label = 'held out actuals',
color = 'darkblue',
alpha = .75,
)
plt.show()
[21]:
test_results = pd.DataFrame(index = f.history.keys(),columns = ['smape','mase'])
for k, v in f.history.items():
test_results.loc[k,['smape','mase']] = [
metrics.smape(test_set,v['Forecast']),
metrics.mase(test_set,v['Forecast'],m=24,obs=f.y),
]
test_results.sort_values('smape')
[21]:
| smape | mase | |
|---|---|---|
| catboost_all_reg | 0.028472 | 0.47471 |
| catboost_signals_only | 0.029847 | 0.508708 |
| rnn_tanh_activation | 0.030332 | 0.482463 |
| manual_arima | 0.032933 | 0.542456 |
| catboost_lags_only | 0.035468 | 0.58522 |
| prophet | 0.039312 | 0.632253 |
| naive | 0.052629 | 0.827014 |
| rnn_relu_activation | 0.053967 | 0.844506 |
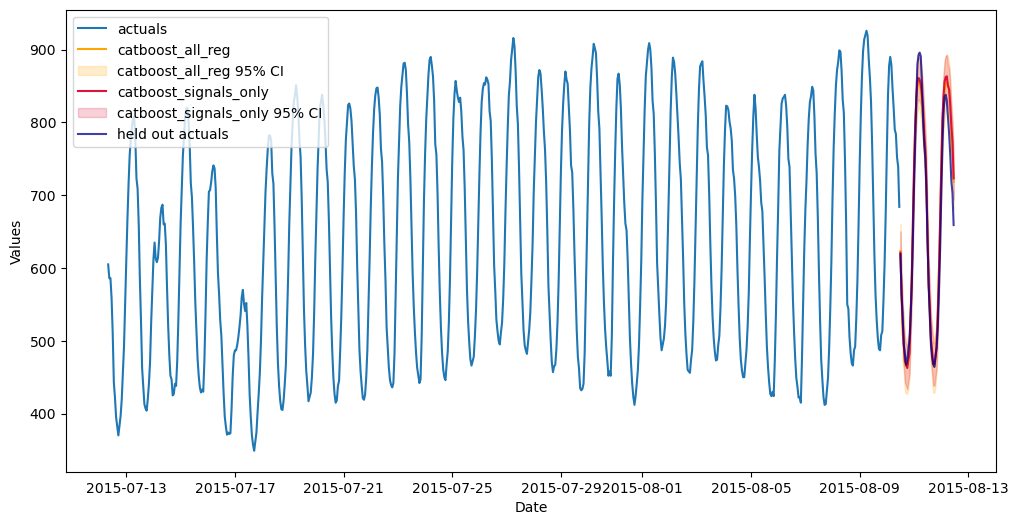
Now, we finally get to the crux of the analysis, where we can see that the catboost that used both the other model signals and the series lags performed best, followed by the catboost model that used only signals. This demonstrates the power of stacking and how it can make good models great.
[22]:
fig, ax = plt.subplots(figsize=(12,6))
f.plot(
models = ['catboost_all_reg','catboost_signals_only'],
ci=True,
ax = ax
)
sns.lineplot(
x = f.future_dates,
y = test_set,
ax = ax,
label = 'held out actuals',
color = 'darkblue',
alpha = .75,
)
plt.show()
View each covariate’s shapley score
Looking at the scores below, it is not surprising that the ARIMA signal was deemed the most important covariate in the final catboost model.
[23]:
f.export_feature_importance('catboost_all_reg')
[23]:
| weight | std | |
|---|---|---|
| feature | ||
| signal_manual_arima | 43.409875 | 19.972339 |
| AR1 | 23.524131 | 12.268015 |
| signal_prophet | 15.545415 | 7.210582 |
| AR3 | 5.498856 | 3.197898 |
| AR48 | 5.287357 | 2.185925 |
| signal_rnn_relu_activation | 4.786888 | 1.545580 |
| AR46 | 4.122075 | 1.869779 |
| AR24 | 3.416473 | 1.909012 |
| AR9 | 3.280298 | 1.027637 |
| AR11 | 3.267605 | 1.200242 |
| signal_rnn_tanh_activation | 3.182172 | 1.265836 |
| AR2 | 3.127812 | 2.230522 |
| AR4 | 3.036603 | 1.894097 |
| AR47 | 2.989912 | 2.134603 |
| AR22 | 2.936120 | 1.500898 |
| AR23 | 2.886598 | 1.646012 |
| AR26 | 2.857151 | 1.606732 |
| AR37 | 2.742366 | 1.151931 |
| AR45 | 2.487890 | 1.208743 |
| signal_naive | 2.312755 | 1.719179 |
| AR32 | 2.220659 | 1.607538 |
| AR10 | 1.983458 | 1.114602 |
| AR35 | 1.774869 | 0.631349 |
| AR44 | 1.684264 | 0.795448 |
| AR38 | 1.400866 | 0.727546 |
| AR25 | 1.397472 | 1.024810 |
| AR20 | 1.394218 | 0.849565 |
| AR19 | 1.340780 | 1.050531 |
| AR15 | 1.153406 | 0.850390 |
| AR5 | 1.152500 | 1.552131 |
| AR27 | 1.087360 | 0.692808 |
| AR13 | 1.021683 | 0.483840 |
| AR12 | 0.956608 | 0.690090 |
| AR33 | 0.952559 | 0.603423 |
| AR30 | 0.870104 | 0.833138 |
| AR6 | 0.785105 | 0.742930 |
| AR14 | 0.782419 | 0.431874 |
| AR29 | 0.741190 | 0.518606 |
| AR17 | 0.726336 | 0.489545 |
| AR8 | 0.720186 | 0.613533 |
| AR18 | 0.694779 | 0.615912 |
| AR42 | 0.640053 | 0.504591 |
| AR28 | 0.637528 | 0.431281 |
| AR39 | 0.620131 | 0.728132 |
| AR36 | 0.612843 | 0.565509 |
| AR31 | 0.589739 | 0.449994 |
| AR34 | 0.574390 | 0.679812 |
| AR16 | 0.568558 | 0.539353 |
| AR7 | 0.554511 | 0.520831 |
| AR40 | 0.515242 | 0.359853 |
| AR21 | 0.506977 | 0.641584 |
| AR41 | 0.273889 | 0.300270 |
| AR43 | 0.222464 | 0.264377 |
[ ]: